【場景描述】采集豆瓣影評數據�����,以采集《夢華錄》影評為例��。
【源網站介紹】豆瓣提供圖書�、電影���、音樂唱片的推薦�����、評論和價格比較����,以及城市獨特的文化生活����。
【使用工具】前嗅ForeSpider數據采集系統����,免費下載:
ForeSpider免費版本下載地址
【入口網址】https://movie.douban.com/subject/35231822/reviews
【采集內容】
采集豆瓣上電視劇《夢華錄》的影評數據����,采集字段:標題����、發布者昵稱��、發布時間���、發布正文����。

【采集效果】
如下圖所示:

l 思路分析
配置思路概覽:

l 配置步驟
1.新建采集任務
選擇【采集配置】�����,點擊任務列表右上方【+】號可新建采集任務���,將采集入口地址填寫在【采集地址】框中���,【任務名稱】自定義即可����,點擊下一步���。

2.獲取翻頁鏈接
采用鏈接過濾的方法來抽取翻頁鏈接��,具體如下所示:①先觀察翻頁鏈接規律�����,找到規律��,很明顯翻頁鏈接中都包含:https://movie.douban.com/subject/35231822/reviews?start=

②設置地址過濾��,過濾包含“https://movie.douban.com/subject/35231822/reviews?start=”的鏈接����,這樣就把翻頁鏈接過濾出來了���。

③關聯模板����,將翻頁鏈接抽取��,關聯模板01����。

3.抽取列表鏈接
①新建一個鏈接抽取���,改名為【列表鏈接】�����,將翻頁鏈接抽取改名為【翻頁鏈接】�。
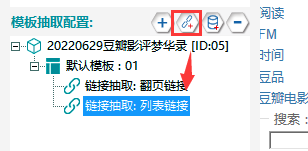
②使用鏈接過濾的方法來獲取列表鏈接��,先采集預覽��,打開列表鏈接預覽結果�,找到帖子鏈接并觀察規律�,發現其中都包括:“https://movie.douban.com/review/+一串數字”

③設置地址過濾�����,過濾包含“https://movie.douban.com/review/+\d”的鏈接�,這樣就把翻頁鏈接過濾出來了�����。其中\d表示數字串����。

4.抽取數據
①新建一個抽取模板�,在其下新建一個數據抽取��,具體操作如下所示:

②數據建表�,按照下圖所示建數據表�。(注意字段屬性等應嚴格按照下圖進行設置)

③將新建好的數據表�����,關聯到模板中去�,如下圖所示:

④填寫示例數據��,采集預覽���,復制任意一條影評鏈接��。

⑤將鏈接粘貼到本模板示例地址中����,并雙擊內置瀏覽器空白部分����,加載本鏈接�����。

⑥關聯模板

⑦數據取值
使用定位取值的方法�����,title字段如下所示:

Nick字段如下所示:

Uptime字段如下所示:

Text字段如下所示:

⑧采集預覽
采集預覽如下圖所示�����,說明配置成功�����,可以開始采集�。如果有哪個字段或者數據沒有出來��,再次檢查之前配置�,正確配置模板�����。

l 采集步驟
模板配置完成��,采集預覽沒有問題后�,可以進行數據采集����。
①建立數據表單:
選擇【數據建表】�����,點擊【表單列表】中該模板的表單�,在【關聯數據表】中選擇【創建】��,表名稱自定義�,這里命名為【menghualu】(注意命名不能用數字�����、文字和特殊符號)�,點擊【確定】�����。創建完成�����,勾選數據表�����,并點擊右上角保存按鈕����。

②開始采集
選擇【數據采集】����,勾選任務名稱�����,點擊【開始采集】��,則正式開始采集��。

③導出數據
采集結束后�,可以在【數據瀏覽】中�,選擇數據表查看采集數據���,并可以導出數據�。


④導出的文件打開如下圖所示:

本教程僅供教學使用���,嚴禁用于商業用途�!
l 前嗅簡介
前嗅大數據���,國內領先的研發型大數據專家�����,多年來致力于為大數據技術的研究與開發�,自主研發了一整套從數據采集�、分析����、處理�、管理到應用����、營銷的大數據產品�。前嗅致力于打造國內第一家深度大數據平臺���!

.png) 大數據引擎
大數據引擎.png) 大數據應用
大數據應用.png) 大數據底層技術
大數據底層技術.png) ForeSpider軟件
ForeSpider軟件
.png) 采集服務
采集服務.png) 軟件學習
軟件學習.png) 智能分析
智能分析.png) 特征提取
特征提取.png) 智能計算
智能計算.png) 數據可視化
數據可視化.png) 數據分析應用
數據分析應用.png) 系統集成服務
系統集成服務.png) 代碼工具
代碼工具.png) 金融方案
金融方案.png) 制造業&物流
制造業&物流.png) 企業數字化
企業數字化.png) 醫療方案
醫療方案.png) 政務方案
政務方案.png) 實時監測
實時監測.png) 智能分析
智能分析.png) 數據智能挖掘
數據智能挖掘.png) 全網自動采集
全網自動采集.png) 場景智慧采集
場景智慧采集.png) 主題識別采集
主題識別采集







 022-2345 2937
022-2345 2937 185 2247 0110
185 2247 0110 business@forenose.com
business@forenose.com









 022-2345 2937
022-2345 2937 185 2247 0110
185 2247 0110 business@forenose.com
business@forenose.com 前嗅大數據
前嗅大數據