一.場景簡介
場景描述:通過搜狗搜索的知乎搜索欄目�����,按關鍵詞搜索采集知乎正文�����。
入口網址:https://zhihu.sogou.com

采集內容:采集的數據為知乎文章的標題和內容

二.思路分析
采集知乎的關鍵點在于:關鍵詞配置鏈接�、翻頁�����、鏈接抽取����、數據抽取���。配置思路如下所示:
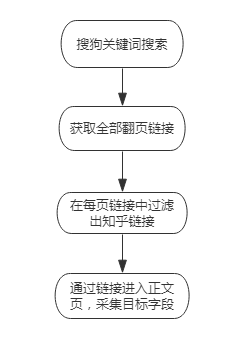
配置思路
三.配置步驟
1. 新建采集任務
選擇【采集配置】����,點擊任務列表右上方【+】號可新建采集任務�����,將采集入口地址填寫在【采集地址】框中����,【任務名稱】自定義即可��。
由于本次采集是通過關鍵詞采集相關內容��,所以【采集類型】要勾選【關鍵詞采集】��,填寫完成��。

點擊【完成】��,任務列表里出現本條任務����,創建成功����。

2. 關鍵詞配置
①在入口頁搜索不同關鍵詞�,發現不同關鍵詞搜索結果的鏈接����,只更換了圖中紅框部分����,而紅框部分正是經過轉碼后的關鍵詞���,于是得出關鍵詞鏈接的拼接規則為:
https://www.sogou.com/sogou?query=關鍵詞
ie=utf8&pid=sogou-wsse-ff111e4a5406ed40&insite=zhihu.com

②得到關鍵詞鏈接拼接規則后���,開始配置關鍵詞搜索:
點擊屏幕右下角【高級配置】����,將采集地址填寫到【請求地址】中����,點擊【+】添加一個參數����,名稱可以自定義���,此項配置是用于后期腳本能將關鍵詞從關鍵詞列表中取出�,配置完成點擊【確定】即可��。

③由于本模板是以關鍵詞搜索為入口���,所以在【模板抽取配置】選擇頻道(即任務名稱)��,選擇【腳本窗口】����,將關鍵詞搜索配置在頻道處即可�����。

④具體配置腳本如下:

⑤效果預覽:
在【關鍵詞列表】中填寫關鍵詞���,點擊【保存】�,點擊【采集預覽】��,即可看到配置效果��。


3. 翻頁配置
關鍵詞配置完成���,下一步是獲取關鍵詞搜索結果中的全部翻頁鏈接���。
①右鍵點擊【默認模板:01】��,選擇添加鏈接抽取����。

②同樣選擇【腳本窗口】�����,配置翻頁腳本���。

③對關鍵詞搜索出的網頁翻頁�����,觀察網頁地址的變化�,發現在原地址中增加了“&sut=2674&sst0=1617764379159&lkt=1%2C1617764379044%2C1617764379044&page=2&ie=utf8”部分���,隨著頁碼的改變�,僅有page參數的值在變化�。page為頁碼的配置參數�����,其它不變部分�����,直接拼接在鏈接中即可���。

④具體配置腳本如下:

⑤效果預覽:

4. 鏈接抽取
這一步是在獲取的翻頁鏈接中����,提取每頁全部知乎問題鏈接:
①在原有模板基礎上�����,右鍵選擇【添加模板】

②右鍵新添加的模板�,選擇【添加鏈接抽取】

③以第一頁為例�����,查看網頁結構(可以使用F12查看�����,但需確認源碼與F12內容一致)�����。
通過查看網頁結構�����,發現所需要的鏈接全部包含在“results”類中�����。每個鏈接塊對應一個“vrwrap”類���,我們所需要的內容�,全部包含在“vrwrap”類的h3結點“vrTitle”中����,“vrTitle”的子結點a標簽內為該條內容的鏈接地址和標題內容�����。


④同樣選擇當前鏈接抽取�����,在【腳本窗口】中編寫腳本���,具體腳本內容如下:

⑤效果預覽:

5. 數據抽取
①鏈接抽取完成進入數據頁���,在原有模板基礎上��,右鍵選擇【添加模板】����,新添加的模板���,右鍵【添加數據抽取】��。
②此時要完成數據建表的工作:
a.選擇【數據建表】���,點擊【采集數據表結構】中的【+】���,即可添加數據表��,名稱可以自定義���。

b.選中數據表���,在數據表結構中點擊【+】�����,添加字段����。如圖所示�,我們需要的字段均以添加到數據表中����,額外添加了網頁地址����、獲取時間����、任務名稱等是為了后期查找內容更方便����。
另外需要注意�,每一個表單都需要配置主鍵字段����,需要使用腳本的字段�����,在高級類型中選擇腳本取值才可進行腳本操作����,其它字段根據實際需求配置即可����。

③數據表配置完成����,選擇【數據抽取】右側數據屬性配置��,表單選擇剛建立的“知乎”數據表��,則可看到表單中的字段在右側顯示�。

④需要配置哪一個字段���,點擊該字段����,在右側字段屬性中配置即可���,選擇腳本配置的字段��,在腳本窗口中進行代碼配置����。
id字段:主鍵字段�,采集內容選擇【主鍵】-【網頁主鍵】�����,主鍵為當前網頁的MD5值�����。

title字段:網頁標題字段��,采集內容選擇【網頁信息】-【網頁標題】

content字段:正文字段��,采集內容選擇【選區內可見文本】-【文章正文內容】

keywords字段:關鍵詞字段����,該字段是用腳本處理的�����,由于關鍵詞字段僅是頻道腳本中的局部變量����,且后期頁面均沒有出現��。
所以需要將關鍵詞字段賦值在全局變量中����,才能在數據抽取時將關鍵詞字段提取出來���,此處將其賦值與全局變量title����。

同理����,數據表中需要采集當前數據在第幾頁出現���,而頁面數據同樣為翻頁模板中的局部變量����,后面模板無法提取�。
所以需要將當前翻頁腳本中的頁數記錄在全局變量中��,同樣將頁數記錄在title中以“#”與關鍵詞分隔�。

當前數據出現在某頁第幾行���,頁碼已經記錄在全局變量title中���,鏈接抽取中當前鏈接行數也是唯一出現的局部變量����,同樣需要記錄才能傳值��,于是將行數也賦值在title中以“*”與頁碼分隔�。

所以最終記錄在title中的值包含以下部分:

對于keywords字段來說�����,取出全局變量title中“#”左邊部分即可���。

page字段:頁碼����,同keywords字段�,取全局變量title中“#”和“*”中間部分���。

raw字段:行數�����,同keywords字段����,取全局變量title中“*”右側部分�����。

gettime字段:網頁采集時間�����,采集內容選擇【時間信息】-【網頁獲取時間】

url字段:網頁地址��,采集內容選擇【網頁信息】-【網頁地址】

web字段:網站名��,腳本返回“知乎”�����。

author字段:可以采用可視化配置��,【采集內容】選擇【選區內可見文本】-【選區內全部文本】���,【定位類型】選擇【標準定位】�����,Ctrl+鼠標左鍵選中選區�,點擊下方【字段定位取值】���,然后確認選區����,字段配置完成���。

temp_name字段:模板名稱��,采集內容選擇【采集任務信息】-【任務名稱】

⑤以上完成全部字段配置�,效果預覽如下:

四.采集步驟
模板配置完成����,采集預覽沒有問題后��,可以進行數據采集��。
①首先要建立采集數據表:
選擇【數據建表】�����,點擊【表單列表】中該模板的表單��,在【關聯數據表】中選擇【創建】���,表名稱自定義�,這里命名為zhihu(注意命名不能用數字和特殊符號)����,點擊【確定】���。

創建完成�,勾選數據表����。

②選擇【數據采集】�,勾選任務名稱����,點擊【開始采集】��,則正式開始采集����。

③可以在【數據瀏覽】中���,選擇數據表查看采集數據�。

五.課堂回顧
GetSearch():返回關鍵詞列表中的關鍵詞�����。

Search():反復調用來遍歷關鍵詞列表���。
FindClass(class名���,標簽類型���,開始查找結點):當符合條件的class名稱唯一時�����,使用class名來查找結點��。
FindName(標簽名,開始查找結點):當查找范圍內�����,符合條件的數據標簽唯一時�����,可以使用標簽名稱查找標簽結點��。
GetTextAll(需要獲取文本的結點,使用的字符編碼):獲取該html標簽節點及所有子節點的可見文本���。
下載本模板鏈接:http://www.bendalayoga.com/view/forespider/view/cases.html

.png) 大數據引擎
大數據引擎.png) 大數據應用
大數據應用.png) 大數據底層技術
大數據底層技術.png) ForeSpider軟件
ForeSpider軟件
.png) 采集服務
采集服務.png) 軟件學習
軟件學習.png) 智能分析
智能分析.png) 特征提取
特征提取.png) 智能計算
智能計算.png) 數據可視化
數據可視化.png) 數據分析應用
數據分析應用.png) 系統集成服務
系統集成服務.png) 代碼工具
代碼工具.png) 金融方案
金融方案.png) 制造業&物流
制造業&物流.png) 企業數字化
企業數字化.png) 醫療方案
醫療方案.png) 政務方案
政務方案.png) 實時監測
實時監測.png) 智能分析
智能分析.png) 數據智能挖掘
數據智能挖掘.png) 全網自動采集
全網自動采集.png) 場景智慧采集
場景智慧采集.png) 主題識別采集
主題識別采集







 022-2345 2937
022-2345 2937 185 2247 0110
185 2247 0110 business@forenose.com
business@forenose.com









 022-2345 2937
022-2345 2937 185 2247 0110
185 2247 0110 business@forenose.com
business@forenose.com 前嗅大數據
前嗅大數據